JSON data can be used in an Import Task, defined in the Data Exchange chapter of Marigold Engage.
It should be known that values held in a JSON structure can't natively be imported into database tables. The processing behind the scenes transforms the JSON structure into one or more CSV streams, which then populate columns in some temporary tables.
From there, a Stored Procedure is required to upsert business data from these rows, which is the 'Data Processing' part of 'Post Processing'. If no post-processing is performed, the data will remain at rest in these temporary tables in the backend.
Note: These temporary tables are only visible through Engage's Data Explorer (or Campaign's SQL pane). The data can't be viewed by people lacking access to these features.
1. Single record import
As an example, we'll begin with a simple JSON file containing just one row of data, which looks like :
{
"fullname" : "Penny Haythere",
"email" : "penny@jmail.nl",
"lang" : "Dutch",
"mobile_number" : "0031 234 567890",
"badge" : "013159"
}Note: You can download this JSON file here.
Example XML describing the JSON structure for this record may look like :
<LOADFORMAT>
<TABLE PATH="" NAME="Records" ROOTTABLE="1">
<COLUMN PATH="fullname" />
<COLUMN PATH="email" />
<COLUMN PATH="lang" />
<COLUMN PATH="mobile_number" NAME="mobile" />
</TABLE>
</LOADFORMAT>Begin by creating a new Import Task, specifying the path as a Public URL (saves having to manage putting the JSON file on an FTP source) :
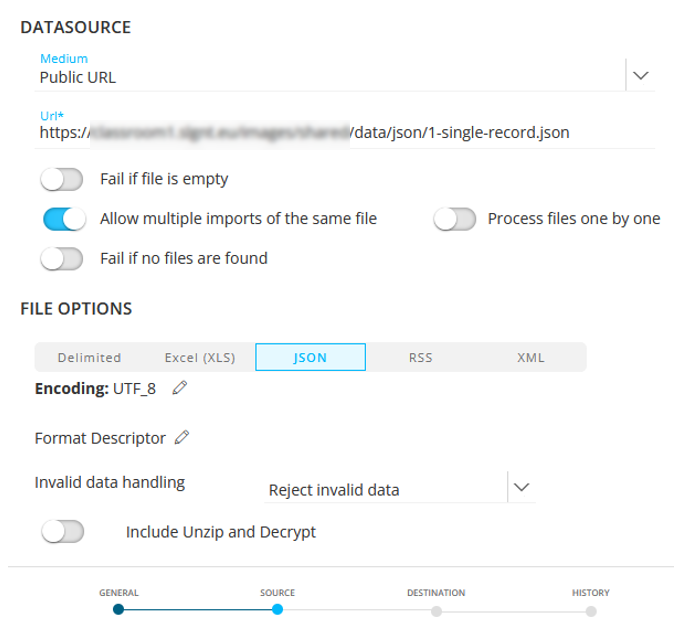
For the Format Descriptor, we'll need to specify the XML that describes this JSON :

Some points about the XML :
- Each JSON key (fullname, email, etc) is specified as a COLUMN in the XML.
- A key that is omitted from the XML will not be considered for import — so in this case, the JSON value for 'badge' is ignored.
- A temporary table will be created, with columns of FULLNAME, EMAIL and LANG.
- The last column will be called MOBILE, as the 'NAME' attribute specifies the column name. If NAME is omitted, the columns will default to the PATH specifications (FULLNAME, EMAIL and LANG in this case).
- NAME="Records" indicates the name of the temporary table will be of the format JOB_1234_Records.
- The job number is the Campaign Job ID relating to the import task.
Note: This Job ID isn't viewable in Engage, but can be seen in the email notifications.
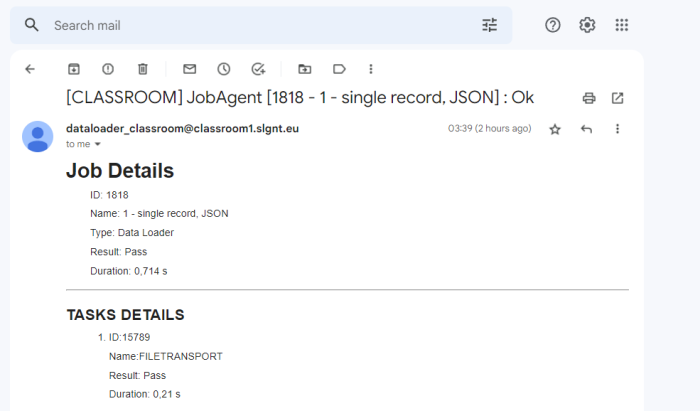
In the example above, Job ID is 1818, type Data Loader refers to the Import Task, with the Name being the import task's name. - The Records suffix was provided in the <TABLE> definition.
- There may be many hierarchical levels appearing in the JSON data, each with their own <TABLE> declaration, but everything will be included in one top level, denoted by ROOTTABLE=1, and an empty PATH value.
- The root element of the XML is always <LOADFORMAT>, so all <TABLE> and <COLUMN> definitions should be included in these elements.
- An XML prologue is not required.
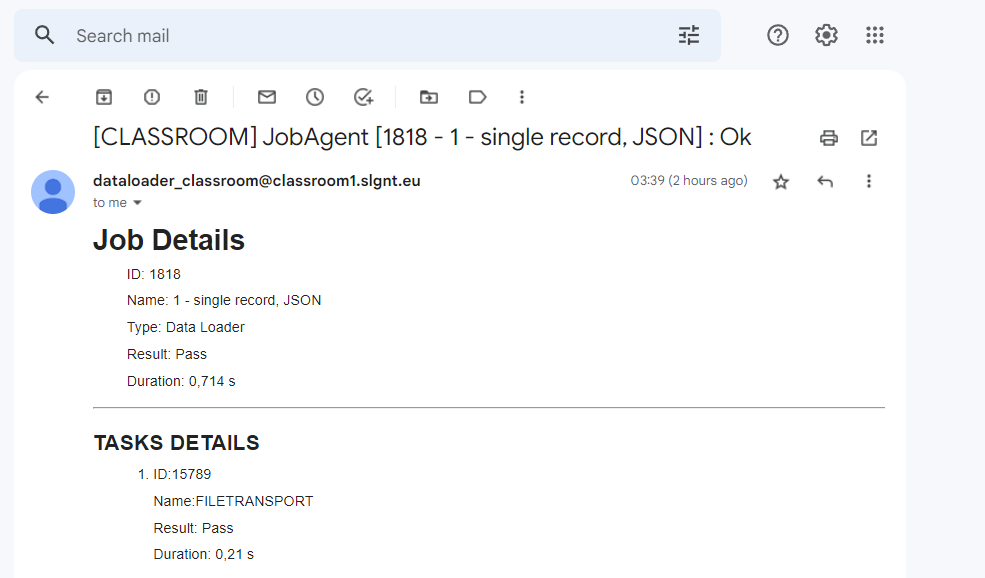
On the next screen, a table name is required:
This is not the name of the temporary tables where the data will reside, but is an intermediate table containing information about the temporary tables created by the CSV streams. This will become clearer later, but for the moment we'll mention the name ‘first’.
Note: A check is made when saving the task, comparing the specified name to one that already exists. If there is a collision, Engage will give an error and refuse to save the task.
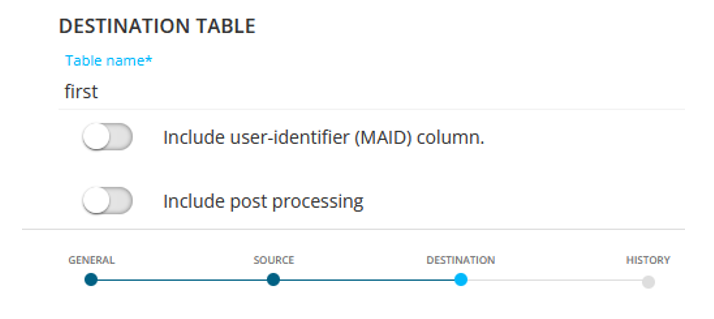
When the job is ran, the history should confirm it worked as intended :
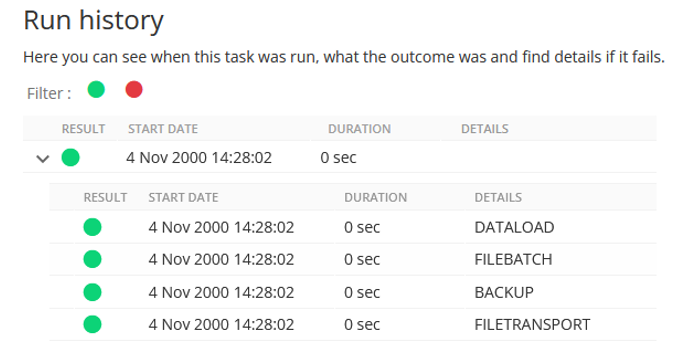
From here, the Data Explorer can be used to reveal what happened to the data. Searching by the name specified as the Destination Table shows that a new table of this name exists :
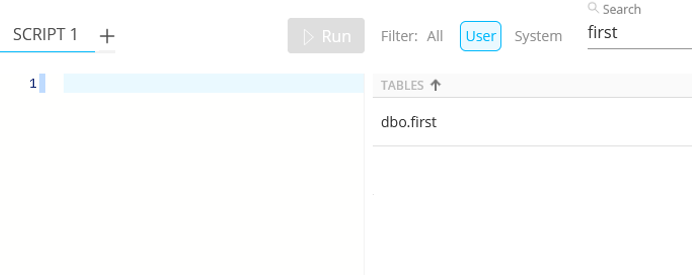
Querying this table reveals just one row containing the 'JOB_[ID]_Records' table name (i.e. one CSV file) :
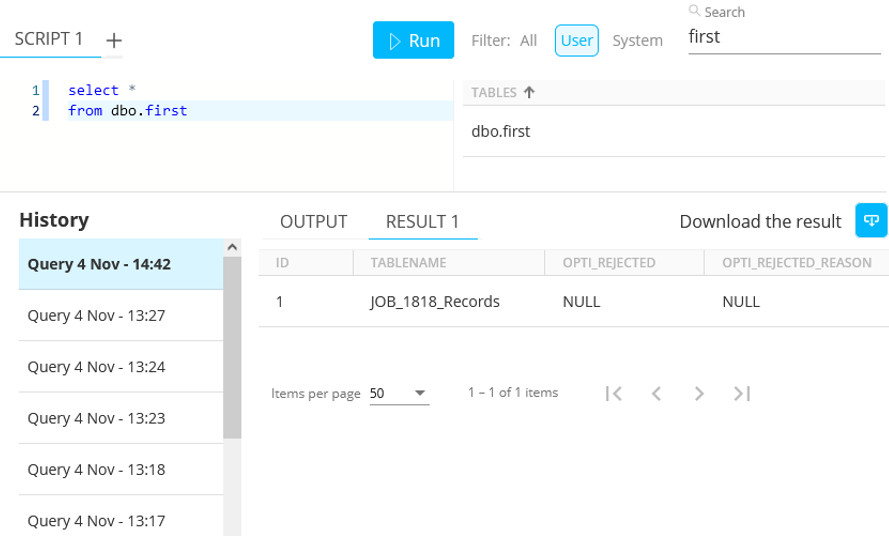
Querying this table (JOB_1818_Records) shows the data itself :
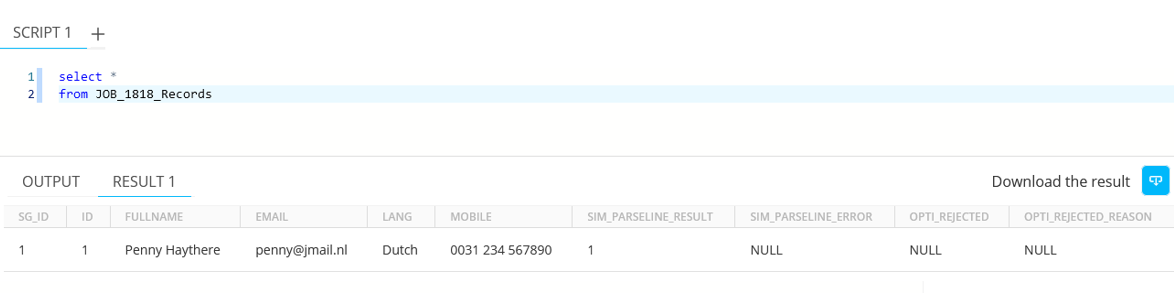
As expected:
- The tablename contains the _RECORDS suffix from the Format Descriptor.
- The NAME attribute created the MOBILE column.
- FULLNAME, EMAIL and LANG columns defaulted to the entries in the PATH, lacking a NAME.
2. Multiple record import
To extend the previous example, this time the JSON file contains multiple records in an array:
[
{
"fullname" : "Dwayne Rodriguez",
"email" : "rodriguez@laredo.mx",
"lang" : "Spanish",
"mobile_number" : "0052 345 667788"
},
{
"fullname" : "Gottlieb Kiesel",
"email" : "dr.kiesel@hesse.edu.de",
"lang" : "German",
"mobile_number" : "0049 123 445566"
},
{
"fullname" : "Fulbert le Fou",
"email" : "inventor@barn.fr",
"lang" : "French",
"mobile_number" : "0033 456 789789"
}
]Note: You can download this JSON file here.
The Format Descriptor used to describe the previous JSON data structure will also suffice here. But we'll make a few changes :
<LOADFORMAT>
<TABLE PATH="" NAME="multiple" ROOTTABLE="1">
<COLUMN PATH="fullname" />
<COLUMN PATH="email" NAME="mail"/>
<COLUMN PATH="lang" />
<COLUMN PATH="mobile_number" NAME="mobile" />
</TABLE>
</LOADFORMAT>In this case :
- Columns of FULLNAME, MAIL, LANG and MOBILE will be populated.
- They will exist in a table called something like JOB_1820_MULTIPLE.
- The name of this table will be a single row mentioned in the intermediate table (previously "first").
3. Multiple records with single subkeys
In this situation, rather than a flat structure, each record may have additional information specified as subkeys (one level deeper), possibly matching 1:1 related data :
[
{
"fullname" : "Dwayne Rodriguez",
"email" : "rodriguez@laredo.mx",
"lang" : "Spanish",
"mobile_number" : "0052 345 667788",
"workdetails" :
{
"office" : "Tijuana",
"payrollNo" : 11223344
}
},
{
"fullname" : "Gottlieb Kiesel",
"email" : "dr.kiesel@hesse.edu.de",
"lang" : "German",
"mobile_number" : "0049 123 445566",
"workdetails" :
{
"office" : "Berlin",
"payrollNo" : 55667788
}
},
{
"fullname" : "Fulbert le Fou",
"email" : "inventor@barn.fr",
"lang" : "French",
"mobile_number" : "0033 456 789789",
"workdetails" :
{
"office" : "Paris",
"payrollNo" : 99001122
}
}
]Note: You can download this JSON file here.
An example Format Descriptor may look like :
<LOADFORMAT>
<TABLE PATH="" NAME="csvfile1" ROOTTABLE="1">
<COLUMN PATH="fullname" />
<COLUMN PATH="email" />
<COLUMN PATH="lang" />
<COLUMN PATH="mobile_number" NAME="mobile" />
<COLUMN PATH="workdetails.office" NAME="workdetails_office"/>
<COLUMN PATH="workdetails.payrollNo" NAME="workdetails_payrollNo"/>
</TABLE>
</LOADFORMAT>
We will specify an intermediate table with the name 'multiple' :

When the job has run, we find a table called 'multiple', containing one row: JOB_1820_csvfile1.
Interrogating this table, we see :
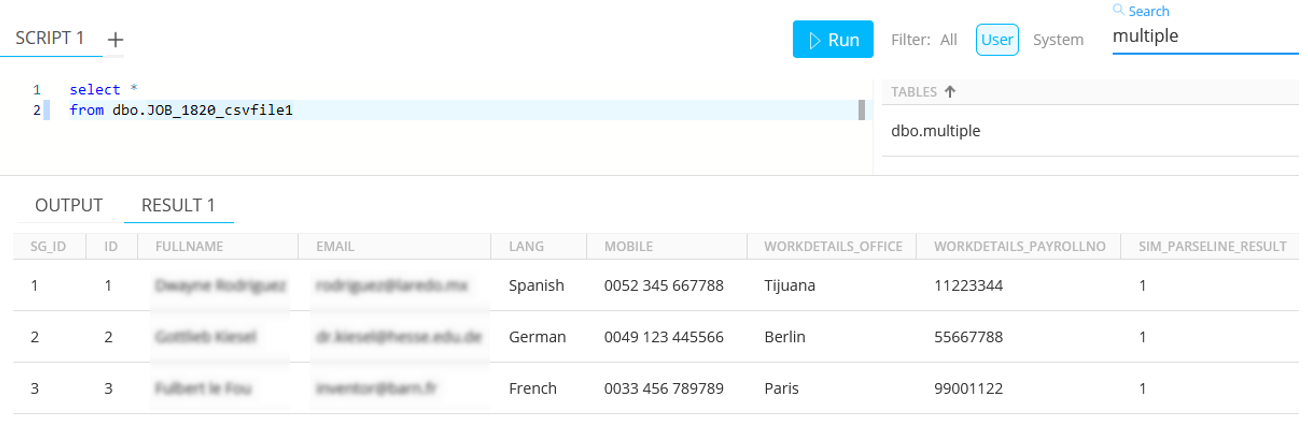
Note:
- PATH="workdetails.office" uses a dot as a level separator
- NAME="workdetails_office" is the name given to the table column created in this holding table
- Csvfile1 is the name given to this table by the Format Descriptor
4. Multiple records with multiple subkeys
This time the JSON file contains multiple records, in which each record may also have an array of multiple related records, simulating a 1:N relationship.
[
{
"fullname" : "Dwayne Rodriguez",
"email" : "rodriguez@laredo.mx",
"lang" : "Spanish",
"mobile_number" : "0052 345 667788",
"subscriptions" : [
{ "magazine" : "GH", "start" : "2016-01-10" }
]
},
{
"fullname" : "Gottlieb Kiesel",
"email" : "dr.kiesel@hesse.edu.de",
"lang" : "German",
"mobile_number" : "0049 123 445566",
"subscriptions" : [
{ "magazine" : "GH", "start" : "2017-05-11" },
{ "magazine" : "SI", "start" : "2018-07-12" }
]
},
{
"fullname" : "Fulbert le Fou",
"email" : "inventor@barn.fr",
"lang" : "French",
"mobile_number" : "0033 456 789789",
"subscriptions" : [
{ "magazine" : "GH", "start" : "2019-09-14" },
{ "magazine" : "SI", "start" : "2020-10-16" },
{ "magazine" : "FM", "start" : "2021-11-18" },
{ "magazine" : "KG", "start" : "2022-12-20" }
]
},
{
"fullname" : "Fiona Starr",
"email" : "hellfire@chopper.edf",
"lang" : "EN",
"mobile_number" : "0044 7890 112233",
"subscriptions" : [ ]
}
]
Note: You can download this JSON file here.
An example Format Descriptor may be :
<LOADFORMAT>
<TABLE PATH="" NAME="toplevel" ROOTTABLE="1">
<COLUMN PATH="fullname" />
<COLUMN PATH="email" />
<COLUMN PATH="lang" />
<COLUMN PATH="mobile_number" NAME="mobile" />
<TABLE PATH="subscriptions" NAME="related">
<COLUMN PATH="magazine" NAME="periodical"/>
<COLUMN PATH="start" NAME="START_DT"/>
</TABLE>
</TABLE>
</LOADFORMAT>In this case
- NAME="toplevel" is the name given to the first table by the Format Descriptor.
- <TABLE PATH="subscriptions" identifies the nested array, to be treated as data to populate a second table. The name of this will be influenced by NAME="related" (the final name will contain a toplevel_related suffix).
- The COLUMN definitions within this <TABLE> element refer to the JSON keys within the array, building the fields in the second table.
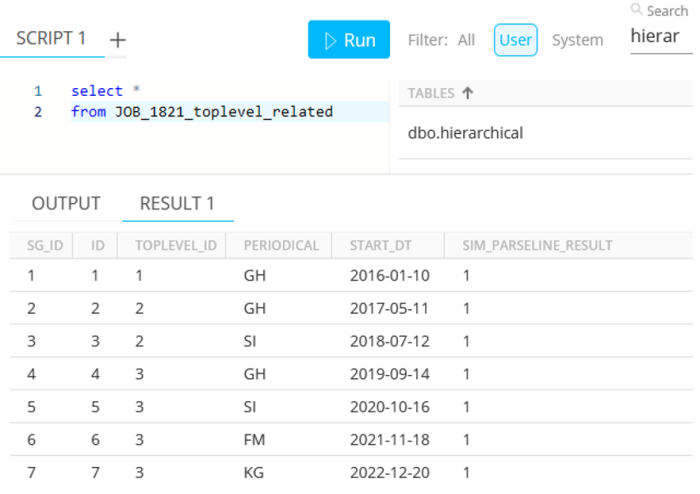
The intermediate table picked is called 'hierarchical' :
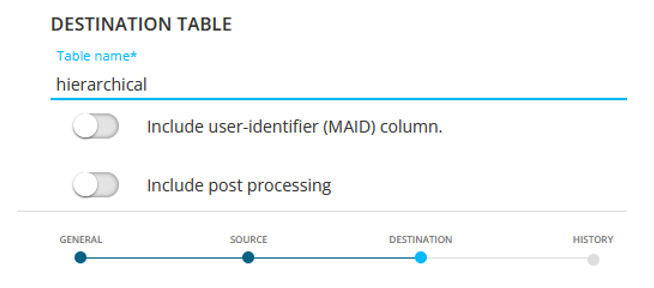
The results are :
-
Dbo.hierarchical contains two rows, showing the table names :
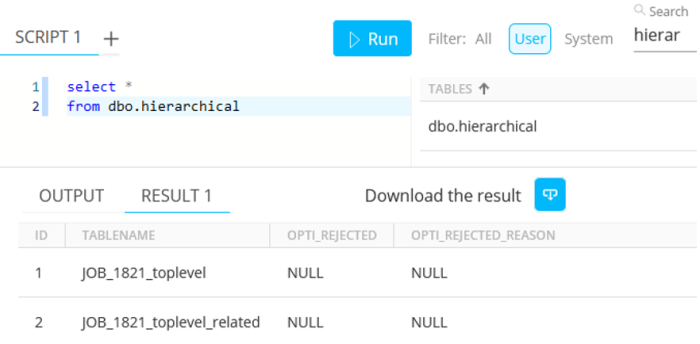
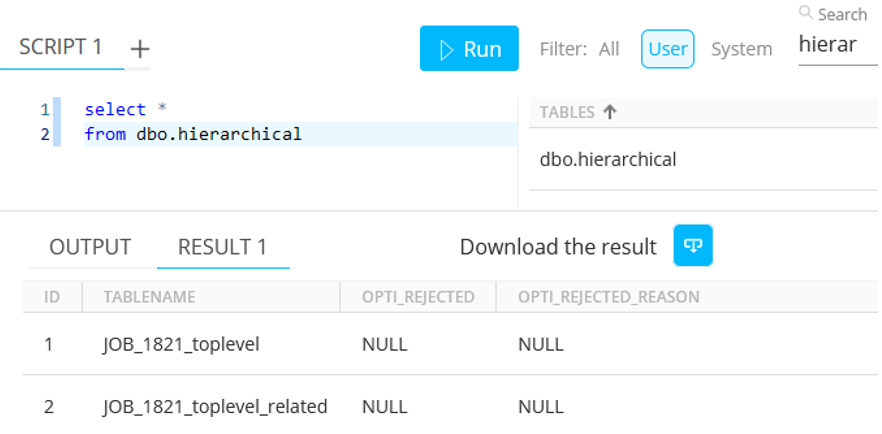
-
JOB_1821_toplevel — Table which contains 4 rows of the 'primary keys' :
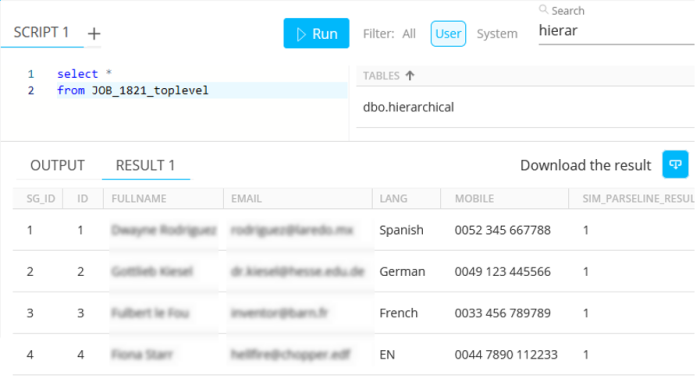
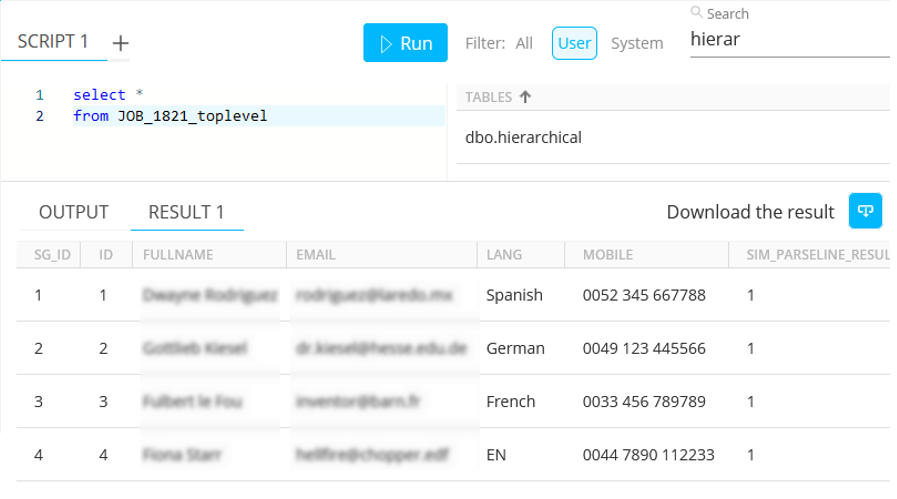
-
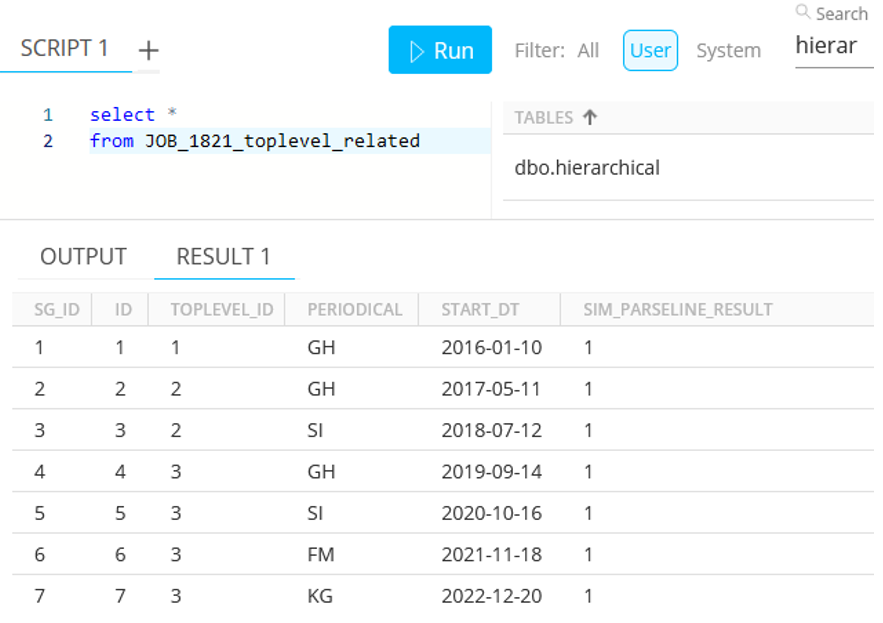
JOB_1821_toplevel_related — Table which contains 7 rows, where "TOPLEVEL_ID" is a Foreign Key relating to the ID of the previous table :